# Shoal框架:如何减少Aptos上的Bullshark延迟?## 概述Aptos labs解决了DAG BFT中两个重要的开放问题,大幅减少了延迟,首次消除了确定性实际协议中对暂停的需求。总体上,在无故障情况下将Bullshark的延迟改进了40%,在故障情况下改进了80%。Shoal是一个通过流水线和领导者声誉增强基于Narwhal的共识协议的框架。流水线通过每轮引入锚点来减少DAG排序延迟,领导者声誉通过确保锚点与最快的验证节点关联来进一步改善延迟。此外,领导者声誉使Shoal可以利用异步DAG构造来消除所有场景中的超时。这允许Shoal提供普遍响应的属性,包含通常需要的乐观响应。该技术非常简单,涉及按顺序运行底层协议的多个实例。当使用Bullshark实例化时,就像一群正在进行接力赛的"鲨鱼"。## 动机在追求区块链网络高性能时,人们一直关注降低通信复杂性。然而,这种方法并没有导致吞吐量显著提高。例如,Diem早期版本中实现的Hotstuff仅实现了3500 TPS,远低于100k+ TPS的目标。近期突破源于认识到数据传播是基于领导者协议的主要瓶颈,可以从并行化中受益。Narwhal系统将数据传播与核心共识逻辑分离,提出了一种架构,所有验证者同时传播数据,共识组件仅订购少量元数据。Narwhal论文报告了160,000 TPS的吞吐量。之前介绍的Quorum Store将数据传播与共识分离,用于扩展当前的共识协议Jolteon。Jolteon是一种基于领导者的协议,结合了Tendermint的线性快速路径和PBFT风格的视图更改,可将Hotstuff延迟降低33%。然而,基于领导者的共识协议无法充分利用Narwhal的吞吐量潜力。因此决定在Narwhal DAG之上部署Bullshark,一种零通信开销的共识协议。但Bullshark的DAG结构带来了50%的延迟代价。本文介绍了Shoal如何大幅减少Bullshark延迟。## DAG-BFT背景Narwhal DAG中每个顶点与一个轮数相关联。进入第r轮,验证者必须获得第r-1轮的n-f个顶点。每个验证者每轮可广播一个顶点,每个顶点至少引用前一轮的n-f个顶点。由于网络异步性,不同验证者可能在任何时间点观察到DAG的不同本地视图。DAG的一个关键属性是不模棱两可的:如果两个验证节点在DAG本地视图中具有相同顶点v,那么它们具有完全相同的v因果历史。## 总顺序可以在没有额外通信开销的情况下就DAG中所有顶点的总顺序达成一致。DAG-Rider、Tusk和Bullshark中的验证者将DAG结构解释为一种共识协议,顶点代表提案,边代表投票。所有现有基于Narwhal的共识协议都具有以下结构:1. 预定锚点:每隔几轮有一个预先确定的领导者,领导者的顶点称为锚点。2. 排序锚点:验证者独立但确定性地决定订购哪些锚点以及跳过哪些锚点。3. 排序因果历史:验证者一个一个处理有序锚点列表,对每个锚点的因果历史中所有先前无序顶点进行排序。满足安全性的关键是确保在步骤2中,所有诚实验证节点创建一个有序锚点列表,所有列表共享相同的前缀。在Shoal中,我们观察到所有验证者都同意第一个有序的锚点。## Bullshark延迟Bullshark的延迟取决于DAG中有序锚点之间的轮数。虽然部分同步版本比异步版本延迟更好,但远非最佳。主要有两个问题:1. 平均块延迟:常见情况下,奇数轮顶点需要三轮,偶数轮非锚点顶点需要四轮才能排序。2. 故障情况延迟:如果一轮领导者未能及时广播锚点,则前几轮未排序顶点必须等待下一个锚点排序,显著降低了地理复制网络的性能。## Shoal框架Shoal通过流水线增强Bullshark,允许每轮有一个锚点,将所有非锚点顶点的延迟减少到三轮。Shoal还引入了零开销领导者声誉机制,偏向选择快速领导者。## 挑战在DAG协议中,流水线和领导者声誉被认为是困难问题:1. 之前的流水线尝试修改核心Bullshark逻辑,但这本质上似乎不可能。2. 领导者声誉可能导致完全不同的排序,而验证者需要就有序历史达成一致以选择未来的锚。作为问题难度的证据,目前生产环境中的Bullshark实现都不支持这些特性。## 协议Shoal依靠在DAG上执行本地计算,实现了保存和重新解释前几轮信息的能力。利用所有验证者都同意第一个有序锚点的洞察,Shoal按顺序组合多个Bullshark实例进行流水线处理,使得:1. 第一个有序锚点是实例的切换点2. 锚点的因果历史用于计算领导者声誉### 流水线Shoal一个接一个运行Bullshark实例,每个实例订购一个锚,触发切换到下一个实例。最初,Shoal在DAG第一轮启动第一个Bullshark实例,运行直到确定第一个有序锚点(比如在第r轮)。所有验证者同意这个锚点,因此可以确定地同意从第r+1轮重新解释DAG。Shoal在第r+1轮启动新的Bullshark实例。理想情况下,这允许Shoal每轮订购一个锚点。### 领导者声誉当Bullshark跳过锚点时,延迟会增加。Shoal通过声誉机制为每个验证节点分配分数,确保将来不太可能选择缓慢的领导者。在每次分数更新时,确定性地重新计算从轮次到领导者的映射F,偏向高分领导者。为了让验证者在新映射上达成一致,他们应该在分数上达成一致。流水线和领导声誉可以自然结合,因为它们都使用相同的核心技术,即在就第一个有序锚点达成一致后重新解释DAG。### 无需超时超时在基于leader的确定性部分同步BFT实现中起关键作用,但引入了复杂性并显著增加延迟。Shoal观察到DAG构造提供了估计网络速度的"时钟"。只要n-f个诚实验证者继续向DAG添加顶点,轮次就会继续前进。最终,当无故障领导者足够快地广播锚点时,锚点的整个因果历史将被排序。避免超时和领导声誉密切相关。重复等待缓慢领导者会增加延迟,而声誉机制排除了缓慢验证者被选为领导者。### 普遍响应Shoal提供了普遍响应的属性,即使在领导者失败或网络异步的情况下也能以网络速度运行。这优于Hotstuff的乐观响应概念。## 评估实现了Bullshark和Shoal,并与Jolteon进行了比较。主要发现:1. 无超时的Baseline Bullshark在出现故障时表现最佳。2. Shoal的流水线和领导者声誉机制显著改善了Bullshark延迟。3. 在50次失败中有16次失败时,Shoal的延迟比Baseline Bullshark低65%。4. Jolteon无法扩展到超过20个验证节点,吞吐量约为Bullshark/Shoal的一半。总的来说,Shoal极大地改善了Bullshark延迟,在高负载下应该可以与Jolteon的端到端延迟相匹配。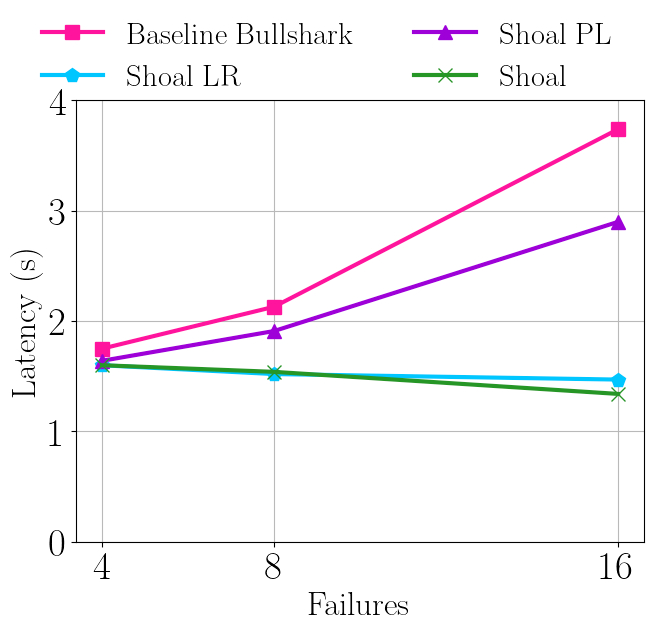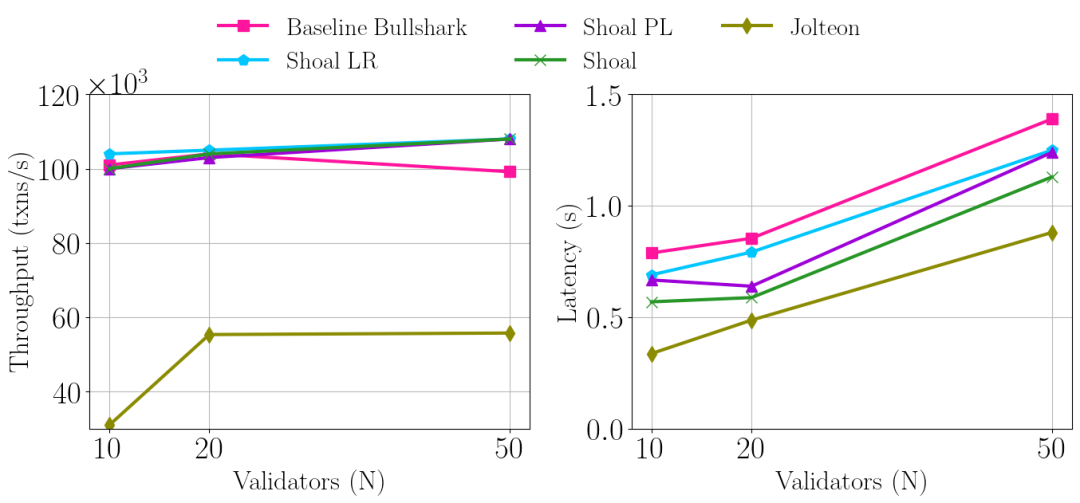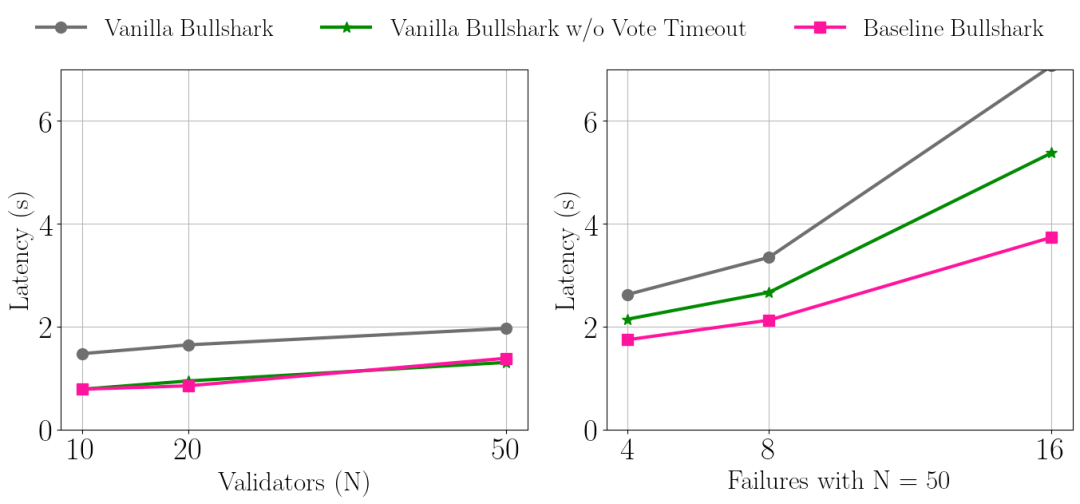


Shoal框架大幅提升Aptos区块链性能 延迟降低40%-80%
Shoal框架:如何减少Aptos上的Bullshark延迟?
概述
Aptos labs解决了DAG BFT中两个重要的开放问题,大幅减少了延迟,首次消除了确定性实际协议中对暂停的需求。总体上,在无故障情况下将Bullshark的延迟改进了40%,在故障情况下改进了80%。
Shoal是一个通过流水线和领导者声誉增强基于Narwhal的共识协议的框架。流水线通过每轮引入锚点来减少DAG排序延迟,领导者声誉通过确保锚点与最快的验证节点关联来进一步改善延迟。此外,领导者声誉使Shoal可以利用异步DAG构造来消除所有场景中的超时。这允许Shoal提供普遍响应的属性,包含通常需要的乐观响应。
该技术非常简单,涉及按顺序运行底层协议的多个实例。当使用Bullshark实例化时,就像一群正在进行接力赛的"鲨鱼"。
动机
在追求区块链网络高性能时,人们一直关注降低通信复杂性。然而,这种方法并没有导致吞吐量显著提高。例如,Diem早期版本中实现的Hotstuff仅实现了3500 TPS,远低于100k+ TPS的目标。
近期突破源于认识到数据传播是基于领导者协议的主要瓶颈,可以从并行化中受益。Narwhal系统将数据传播与核心共识逻辑分离,提出了一种架构,所有验证者同时传播数据,共识组件仅订购少量元数据。Narwhal论文报告了160,000 TPS的吞吐量。
之前介绍的Quorum Store将数据传播与共识分离,用于扩展当前的共识协议Jolteon。Jolteon是一种基于领导者的协议,结合了Tendermint的线性快速路径和PBFT风格的视图更改,可将Hotstuff延迟降低33%。然而,基于领导者的共识协议无法充分利用Narwhal的吞吐量潜力。
因此决定在Narwhal DAG之上部署Bullshark,一种零通信开销的共识协议。但Bullshark的DAG结构带来了50%的延迟代价。
本文介绍了Shoal如何大幅减少Bullshark延迟。
DAG-BFT背景
Narwhal DAG中每个顶点与一个轮数相关联。进入第r轮,验证者必须获得第r-1轮的n-f个顶点。每个验证者每轮可广播一个顶点,每个顶点至少引用前一轮的n-f个顶点。由于网络异步性,不同验证者可能在任何时间点观察到DAG的不同本地视图。
DAG的一个关键属性是不模棱两可的:如果两个验证节点在DAG本地视图中具有相同顶点v,那么它们具有完全相同的v因果历史。
总顺序
可以在没有额外通信开销的情况下就DAG中所有顶点的总顺序达成一致。DAG-Rider、Tusk和Bullshark中的验证者将DAG结构解释为一种共识协议,顶点代表提案,边代表投票。
所有现有基于Narwhal的共识协议都具有以下结构:
预定锚点:每隔几轮有一个预先确定的领导者,领导者的顶点称为锚点。
排序锚点:验证者独立但确定性地决定订购哪些锚点以及跳过哪些锚点。
排序因果历史:验证者一个一个处理有序锚点列表,对每个锚点的因果历史中所有先前无序顶点进行排序。
满足安全性的关键是确保在步骤2中,所有诚实验证节点创建一个有序锚点列表,所有列表共享相同的前缀。在Shoal中,我们观察到所有验证者都同意第一个有序的锚点。
Bullshark延迟
Bullshark的延迟取决于DAG中有序锚点之间的轮数。虽然部分同步版本比异步版本延迟更好,但远非最佳。
主要有两个问题:
平均块延迟:常见情况下,奇数轮顶点需要三轮,偶数轮非锚点顶点需要四轮才能排序。
故障情况延迟:如果一轮领导者未能及时广播锚点,则前几轮未排序顶点必须等待下一个锚点排序,显著降低了地理复制网络的性能。
Shoal框架
Shoal通过流水线增强Bullshark,允许每轮有一个锚点,将所有非锚点顶点的延迟减少到三轮。Shoal还引入了零开销领导者声誉机制,偏向选择快速领导者。
挑战
在DAG协议中,流水线和领导者声誉被认为是困难问题:
之前的流水线尝试修改核心Bullshark逻辑,但这本质上似乎不可能。
领导者声誉可能导致完全不同的排序,而验证者需要就有序历史达成一致以选择未来的锚。
作为问题难度的证据,目前生产环境中的Bullshark实现都不支持这些特性。
协议
Shoal依靠在DAG上执行本地计算,实现了保存和重新解释前几轮信息的能力。利用所有验证者都同意第一个有序锚点的洞察,Shoal按顺序组合多个Bullshark实例进行流水线处理,使得:
流水线
Shoal一个接一个运行Bullshark实例,每个实例订购一个锚,触发切换到下一个实例。
最初,Shoal在DAG第一轮启动第一个Bullshark实例,运行直到确定第一个有序锚点(比如在第r轮)。所有验证者同意这个锚点,因此可以确定地同意从第r+1轮重新解释DAG。Shoal在第r+1轮启动新的Bullshark实例。
理想情况下,这允许Shoal每轮订购一个锚点。
领导者声誉
当Bullshark跳过锚点时,延迟会增加。Shoal通过声誉机制为每个验证节点分配分数,确保将来不太可能选择缓慢的领导者。
在每次分数更新时,确定性地重新计算从轮次到领导者的映射F,偏向高分领导者。为了让验证者在新映射上达成一致,他们应该在分数上达成一致。
流水线和领导声誉可以自然结合,因为它们都使用相同的核心技术,即在就第一个有序锚点达成一致后重新解释DAG。
无需超时
超时在基于leader的确定性部分同步BFT实现中起关键作用,但引入了复杂性并显著增加延迟。
Shoal观察到DAG构造提供了估计网络速度的"时钟"。只要n-f个诚实验证者继续向DAG添加顶点,轮次就会继续前进。最终,当无故障领导者足够快地广播锚点时,锚点的整个因果历史将被排序。
避免超时和领导声誉密切相关。重复等待缓慢领导者会增加延迟,而声誉机制排除了缓慢验证者被选为领导者。
普遍响应
Shoal提供了普遍响应的属性,即使在领导者失败或网络异步的情况下也能以网络速度运行。这优于Hotstuff的乐观响应概念。
评估
实现了Bullshark和Shoal,并与Jolteon进行了比较。主要发现:
无超时的Baseline Bullshark在出现故障时表现最佳。
Shoal的流水线和领导者声誉机制显著改善了Bullshark延迟。
在50次失败中有16次失败时,Shoal的延迟比Baseline Bullshark低65%。
Jolteon无法扩展到超过20个验证节点,吞吐量约为Bullshark/Shoal的一半。
总的来说,Shoal极大地改善了Bullshark延迟,在高负载下应该可以与Jolteon的端到端延迟相匹配。