

现在的上币闹剧是:交易所疯狂抬高上币KPI, 项目方全靠嘴炮堆流量. 但其实根本没有买量, 只能空投分期解锁慢慢薅散户韭菜. 这就像拿假鸡巴插飞机杯一样搞笑, 充斥着后现代币圈博弈的离奇
Mirror Tang
用户暂无简介
Mirror Tang
过去大家拼命上云, 但推理阶段的单位算力成本让很多团队意识到:长周期、大规模的 AI 推理在云上烧钱太快. AI 原生应用更适合将关键推理任务下沉到本地机房, 既降低延迟又节省带宽和云租用费用
争夺内存是深度学习训练早期的典型特征(谁的显存大谁赢) , 但今天:
存储到 GPU 的数据吞吐极限直接影响推理 QPS
GPU 与 CPU/加速卡之间的交互速度是流水线性能的上限
单机柜 AI 集群功耗可达数十千瓦,PD设计不合理会直接卡死算力部署规模
如果数据中心布局还停留在 2015 年传统 Web/数据库业务的设计范式,就会在 AI 工作负载下直接翻车
查看我们的见解:
20 Tech Experts On Emerging Hardware Trends Businesses Must Watch via @forbes
争夺内存是深度学习训练早期的典型特征(谁的显存大谁赢) , 但今天:
存储到 GPU 的数据吞吐极限直接影响推理 QPS
GPU 与 CPU/加速卡之间的交互速度是流水线性能的上限
单机柜 AI 集群功耗可达数十千瓦,PD设计不合理会直接卡死算力部署规模
如果数据中心布局还停留在 2015 年传统 Web/数据库业务的设计范式,就会在 AI 工作负载下直接翻车
查看我们的见解:
20 Tech Experts On Emerging Hardware Trends Businesses Must Watch via @forbes
VIA7.74%
- 赞赏
- 点赞
- 评论
- 转发
- 分享
- 赞赏
- 点赞
- 评论
- 转发
- 分享
工作很辛苦,都来测一下吧
久坐、容易累 gohealthy 牡蛎精
间歇性失忆 Swisse 4倍鱼油
缺维生素 Swisse男士复合维生素
熬夜 褪黑素
脱发 Unichi 小熊软糖
高度近视/眼压高 不要用蒸汽眼罩
久坐、容易累 gohealthy 牡蛎精
间歇性失忆 Swisse 4倍鱼油
缺维生素 Swisse男士复合维生素
熬夜 褪黑素
脱发 Unichi 小熊软糖
高度近视/眼压高 不要用蒸汽眼罩

- 赞赏
- 点赞
- 评论
- 转发
- 分享
不让老百姓说话是谁发明的,原来已经2025年了啊 我还以为是大清呢
- 赞赏
- 点赞
- 评论
- 转发
- 分享
- 赞赏
- 点赞
- 评论
- 转发
- 分享
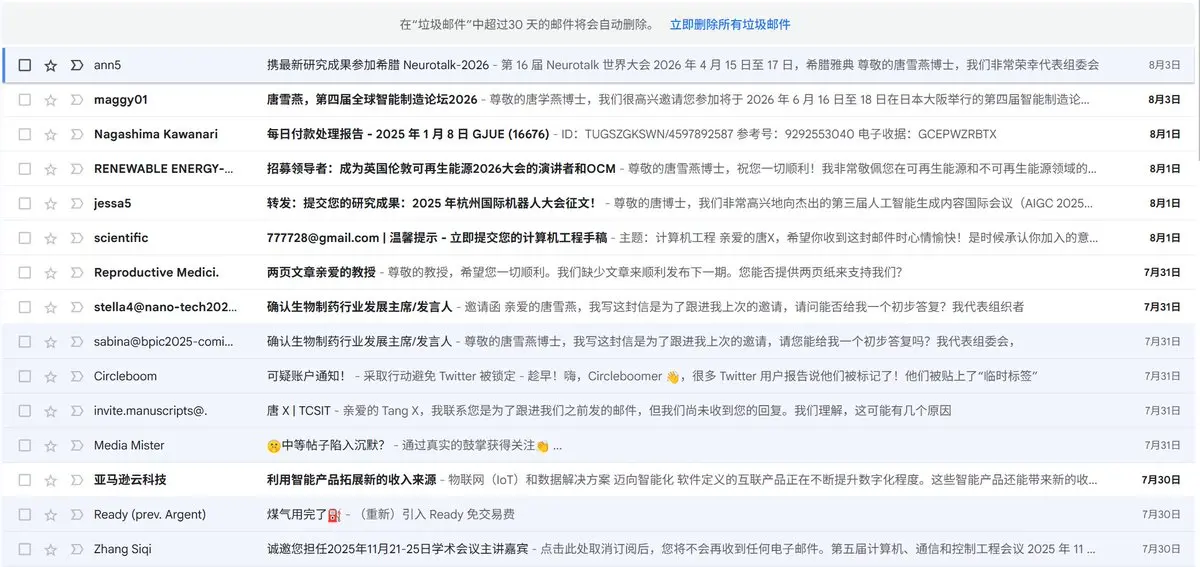
其实我建议大家征稿/邀请演讲的时候做做样子,至少不要明文群发,不然结果就是进垃圾箱
- 赞赏
- 点赞
- 评论
- 转发
- 分享
中国经济已经很畸形了,一线城市大学生日薪还不如停车位高
- 赞赏
- 点赞
- 评论
- 转发
- 分享
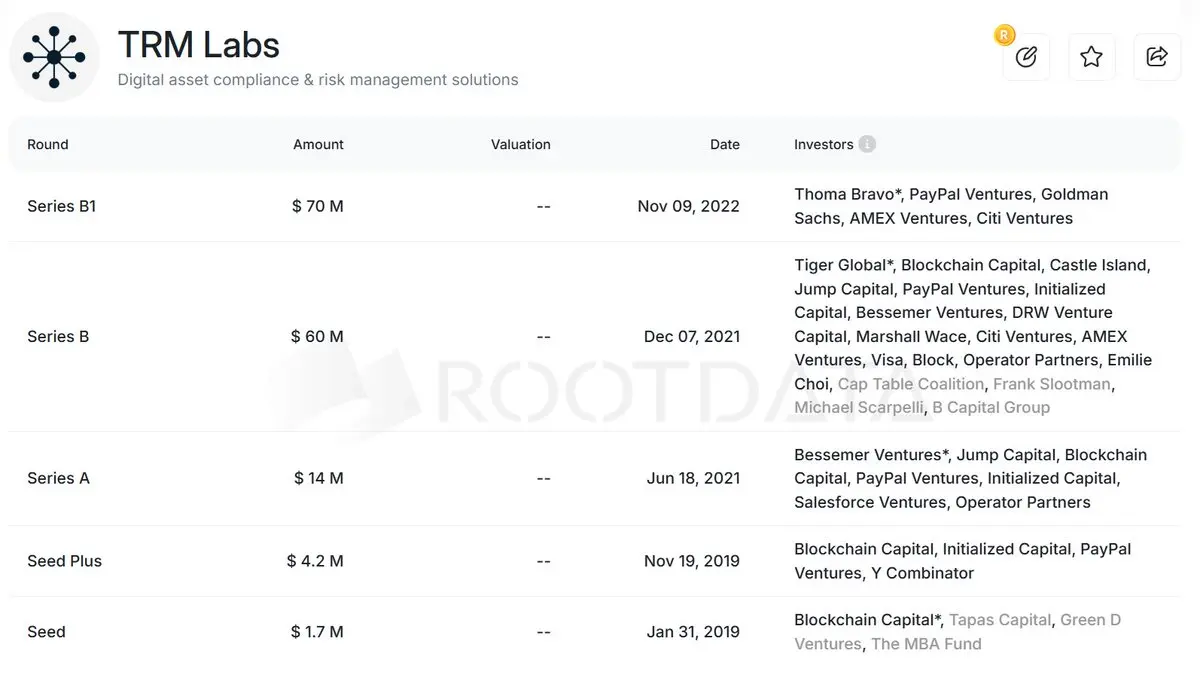
如果慢雾出生在美国
- 赞赏
- 点赞
- 评论
- 转发
- 分享
很难想象我在做什么。
查看原文
- 赞赏
- 点赞
- 评论
- 转发
- 分享
把我的GPT切换到团队模式后的一些直观感受
1.人员管理方便了,可以直接添加或删除成员和分配高级功能
2.可以一键挂载Google Drive、Notion、Github仓库和工作组. 集中资源管理,共享我的全部工作文档
3.单人模式的时候GPT经常犯傻傻逼,多人协作我能很快发现并指出它的傻逼之处,团队成员共享会话历史、知识上下文,不再重复提问
最重要的一点是帮我很好的解决了入职培训问题,知识的火炬哇 在传递
1.人员管理方便了,可以直接添加或删除成员和分配高级功能
2.可以一键挂载Google Drive、Notion、Github仓库和工作组. 集中资源管理,共享我的全部工作文档
3.单人模式的时候GPT经常犯傻傻逼,多人协作我能很快发现并指出它的傻逼之处,团队成员共享会话历史、知识上下文,不再重复提问
最重要的一点是帮我很好的解决了入职培训问题,知识的火炬哇 在传递
GPT5.23%

- 赞赏
- 点赞
- 评论
- 转发
- 分享
我把我的知识交给了团队的所有人😁,我也把我的隐私同步给了团队所有人😑
现在我们有20个Mirror了,不敢想象我们会有多强大
现在我们有20个Mirror了,不敢想象我们会有多强大

- 赞赏
- 点赞
- 评论
- 转发
- 分享
以下是全球租售比超高(最高15%年化)的四个人口虹吸型城市,你会在哪买房?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
如果一个人能力强却混的一般,那么大概率是人品好
- 赞赏
- 点赞
- 评论
- 转发
- 分享
湖南男子朱雀玄武敕令改名后被强行送进精神病院

- 赞赏
- 点赞
- 评论
- 转发
- 分享
湖南男子朱雀玄武敕令改名后被强行送进精神病院
朱雀玄武敕令先生发布了一篇小红书笔记,快来看吧!😆
朱雀玄武敕令先生发布了一篇小红书笔记,快来看吧!😆


- 赞赏
- 点赞
- 评论
- 转发
- 分享
为什么币圈明明是去中心化的理想国,却被一小撮做市商和流量 KOL 精准地操控着?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
技术创始人最常犯的错误是自恋型构建. 把自己当作理想用户,过度在乎功能要多、系统要强而忽略了体验要傻、好用即够.
尤其在早期,用户用你的核心原因是你比替代品方便、便宜、轻松. 要牢记你是为某类有明确痛点的人设计解决方案. 最有效的产品设计不是做我喜欢的,而是做用户愿意继续用的
尤其在早期,用户用你的核心原因是你比替代品方便、便宜、轻松. 要牢记你是为某类有明确痛点的人设计解决方案. 最有效的产品设计不是做我喜欢的,而是做用户愿意继续用的
- 赞赏
- 点赞
- 评论
- 转发
- 分享
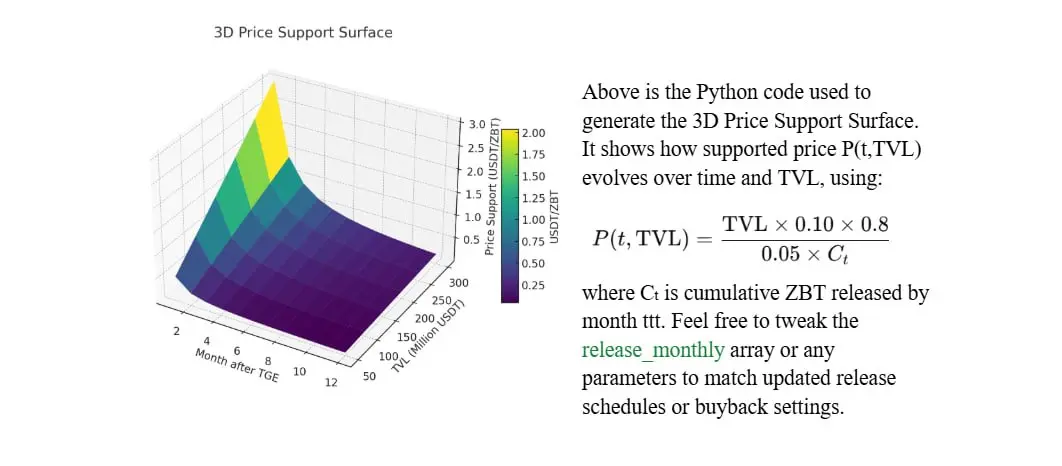
ZEROBASE (ZBT) Price Forecast —— (算着玩的别当真)
Based on TVL Scenarios & Dynamic Buyback Strategies
Based on TVL Scenarios & Dynamic Buyback Strategies
- 赞赏
- 点赞
- 评论
- 转发
- 分享
我不仅努力工作 也很注重身体健康和保养

- 赞赏
- 点赞
- 评论
- 转发
- 分享