

現在的上幣鬧劇是:交易所瘋狂抬高上幣KPI, 項目方全靠嘴炮堆流量. 但其實根本沒有買量, 只能空投分期解鎖慢慢薅散戶韭菜. 這就像拿假雞巴插飛機杯一樣搞笑, 充斥着後現代幣圈博弈的離奇
查看原文Mirror Tang
用戶暫無簡介
Mirror Tang
過去大家拼命上雲, 但推理階段的單位算力成本讓很多團隊意識到:長週期、大規模的 AI 推理在雲上燒錢太快. AI 原生應用更適合將關鍵推理任務下沉到本地機房, 既降低延遲又節省帶寬和雲租用費用
爭奪內存是深度學習訓練早期的典型特徵(誰的顯存大誰贏) , 但今天:
存儲到 GPU 的數據吞吐極限直接影響推理 QPS
GPU 與 CPU/加速卡之間的交互速度是流水線性能的上限
單機櫃 AI 集羣功耗可達數十千瓦,PD設計不合理會直接卡死算力部署規模
如果數據中心布局還停留在 2015 年傳統 Web/數據庫業務的設計範式,就會在 AI 工作負載下直接翻車
查看我們的見解:
20 Tech Experts On Emerging Hardware Trends Businesses Must Watch via @forbes
爭奪內存是深度學習訓練早期的典型特徵(誰的顯存大誰贏) , 但今天:
存儲到 GPU 的數據吞吐極限直接影響推理 QPS
GPU 與 CPU/加速卡之間的交互速度是流水線性能的上限
單機櫃 AI 集羣功耗可達數十千瓦,PD設計不合理會直接卡死算力部署規模
如果數據中心布局還停留在 2015 年傳統 Web/數據庫業務的設計範式,就會在 AI 工作負載下直接翻車
查看我們的見解:
20 Tech Experts On Emerging Hardware Trends Businesses Must Watch via @forbes
VIA6.03%
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
工作很辛苦,都來測一下吧
久坐、容易累 gohealthy 牡蠣精
間歇性失憶 Swisse 4倍魚油
缺維生素 Swisse男士復合維生素
熬夜 褪黑素
脫發 Unichi 小熊軟糖
高度近視/眼壓高 不要用蒸汽眼罩
查看原文久坐、容易累 gohealthy 牡蠣精
間歇性失憶 Swisse 4倍魚油
缺維生素 Swisse男士復合維生素
熬夜 褪黑素
脫發 Unichi 小熊軟糖
高度近視/眼壓高 不要用蒸汽眼罩

- 讚賞
- 點讚
- 留言
- 轉發
- 分享
不讓老百姓說話是誰發明的,原來已經2025年了啊 我還以爲是大清呢
查看原文- 讚賞
- 點讚
- 留言
- 轉發
- 分享
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
其實我建議大家徵稿/邀請演講的時候做做樣子,至少不要明文羣發,不然結果就是進垃圾箱
查看原文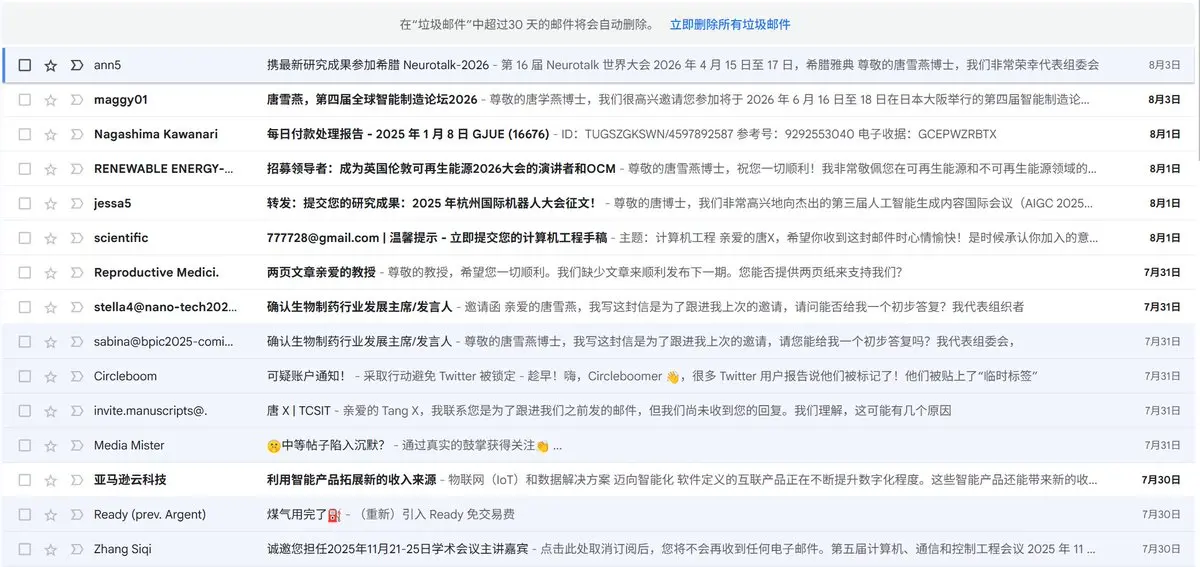
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
中國經濟已經很畸形了,一線城市大學生日薪還不如停車位高
查看原文- 讚賞
- 點讚
- 留言
- 轉發
- 分享
如果慢霧出生在美國
查看原文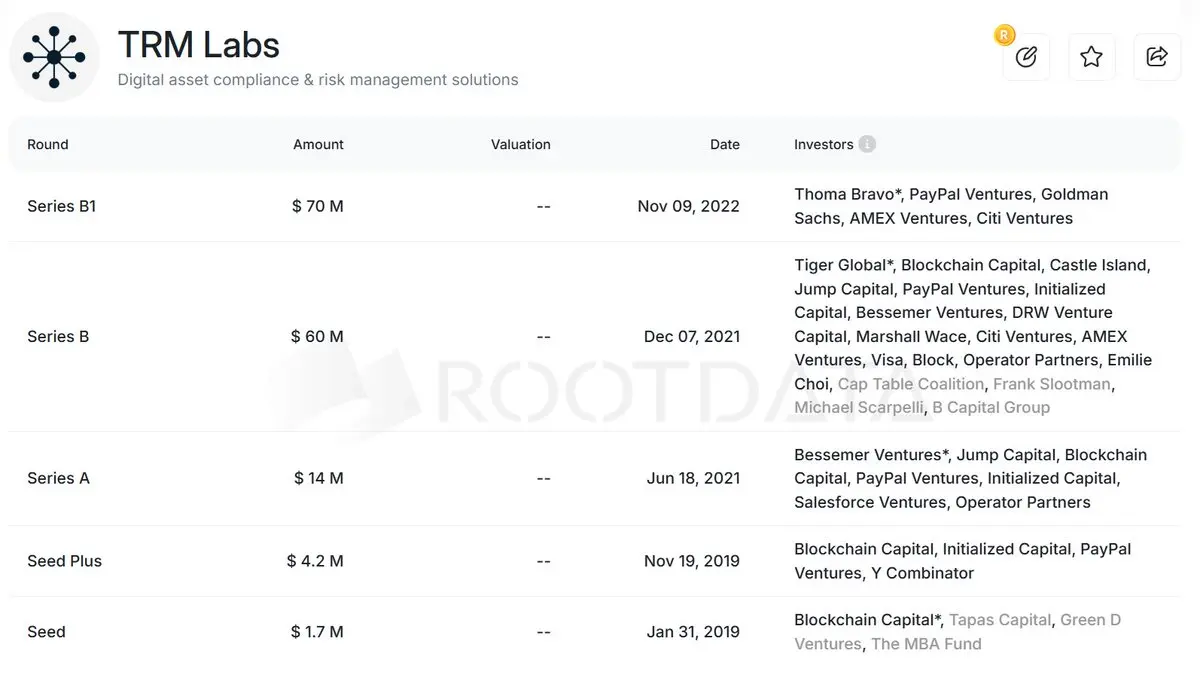
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
很難想象我在做什麼。
查看原文
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
把我的GPT切換到團隊模式後的一些直觀感受
1.人員管理方便了,可以直接添加或刪除成員和分配高級功能
2.可以一鍵掛載Google Drive、Notion、Github倉庫和工作組. 集中資源管理,共享我的全部工作文檔
3.單人模式的時候GPT經常犯傻傻逼,多人協作我能很快發現並指出它的傻逼之處,團隊成員共享會話歷史、知識上下文,不再重復提問
最重要的一點是幫我很好的解決了入職培訓問題,知識的火炬哇 在傳遞
1.人員管理方便了,可以直接添加或刪除成員和分配高級功能
2.可以一鍵掛載Google Drive、Notion、Github倉庫和工作組. 集中資源管理,共享我的全部工作文檔
3.單人模式的時候GPT經常犯傻傻逼,多人協作我能很快發現並指出它的傻逼之處,團隊成員共享會話歷史、知識上下文,不再重復提問
最重要的一點是幫我很好的解決了入職培訓問題,知識的火炬哇 在傳遞
GPT-2.79%

- 讚賞
- 點讚
- 留言
- 轉發
- 分享
我把我的知識交給了團隊的所有人😁,我也把我的隱私同步給了團隊所有人😑
現在我們有20個Mirror了,不敢想象我們會有多強大
查看原文現在我們有20個Mirror了,不敢想象我們會有多強大

- 讚賞
- 點讚
- 留言
- 轉發
- 分享
以下是全球租售比超高(最高15%年化)的四個人口虹吸型城市,你會在哪買房?
查看原文- 讚賞
- 點讚
- 留言
- 轉發
- 分享
如果一個人能力強卻混的一般,那麼大概率是人品好
查看原文- 讚賞
- 點讚
- 留言
- 轉發
- 分享
湖南男子朱雀玄武敕令改名後被強行送進精神病院
查看原文
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
湖南男子朱雀玄武敕令改名後被強行送進精神病院
朱雀玄武敕令先生發布了一篇小紅書筆記,快來看吧!😆
查看原文朱雀玄武敕令先生發布了一篇小紅書筆記,快來看吧!😆


- 讚賞
- 點讚
- 留言
- 轉發
- 分享
爲什麼幣圈明明是去中心化的理想國,卻被一小撮做市商和流量 KOL 精準地操控着?
查看原文- 讚賞
- 點讚
- 留言
- 轉發
- 分享
技術創始人最常犯的錯誤是自戀型構建. 把自己當作理想用戶,過度在乎功能要多、系統要強而忽略了體驗要傻、好用即夠.
尤其在早期,用戶用你的核心原因是你比替代品方便、便宜、輕鬆. 要牢記你是爲某類有明確痛點的人設計解決方案. 最有效的產品設計不是做我喜歡的,而是做用戶願意繼續用的
查看原文尤其在早期,用戶用你的核心原因是你比替代品方便、便宜、輕鬆. 要牢記你是爲某類有明確痛點的人設計解決方案. 最有效的產品設計不是做我喜歡的,而是做用戶願意繼續用的
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
ZEROBASE (ZBT) Price Forecast —— (算着玩的別當真)
Based on TVL Scenarios & Dynamic Buyback Strategies
查看原文Based on TVL Scenarios & Dynamic Buyback Strategies
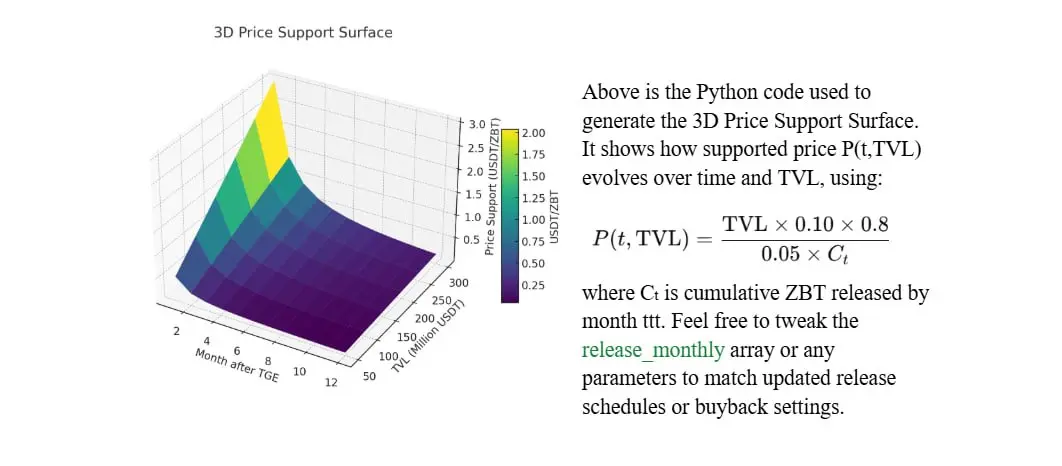
- 讚賞
- 點讚
- 留言
- 轉發
- 分享
我不僅努力工作 也很注重身體健康和保養
查看原文
- 讚賞
- 點讚
- 留言
- 轉發
- 分享